
数据录入工厂——真正实现档案电子化,加速办公现代化管理进程
2023-09-08随着科学技术的不断发展、档案领域新技术的不断涌现、以及办公自动化的进一步普及,传统的档案管理已不能适应新技术发展的需要。如何保管好电子档案已成为当前摆在档案工作者眼前日益突出的问题。
党中央、国务院及全国部分省市党政机关也都采用了无纸办公,我国政府还成立了电子文件归档与电子档案管理研究领导小组,并逐步制定出相应的管理办法,为电子档案广泛的普及打下了基础。此外,金融、事业单位等各行各业都在积极改善和创造条件,纸质档案载体向电子档案管理正在高速发展。
传统手工录入的方式已经不能满足要求,如何将纸质文档转化为电子文件,科学高效的管理电子档案?OCR文字识别是其中必不可缺的一个环节。

中安未来在OCR领域深耕30多年,先后推出多款优秀、实用的OCR文字识别产品:TH-OCR综合文字识别系统、少数民族文字识别系统、IT-scan图档易扫通、TH-OCR数据录入工厂、综合文字识别系统-国产化、通用文字识别产品等,先后在档案馆、报社、图书馆、政府、事业单位等机构成功应用,其中数据录入工厂产品更成为各大机构的首选。

中安数据录入工厂即智能图像识别处理工具,可将各种文档图片转换成可检索的双层PDF/TXT/RTF文件,可识别简体、繁体、手写体、纯英文、日文、韩文等多门语种,实现海量数据电子化,全方位与大型报社、数据加工企业的立体连接。
图像处理功能
支持图像旋转、删除区域、图像裁剪、倾斜校正等多种图像处理,自动对倾斜图像等不规则图像进行校正,增强图像质量,提高识别率。
版面分析
数据录入工厂可对杂志、书本、报刊等进行自动版面分析。将版面分为横排文本、竖排文本、图像、表格四种类型,正确的版面分析可以提高识别效果。用户也可以根据需求,进行手动版面分析。

自学习
针对古籍、科研等特殊领域文档中经常出现的特殊文字,用户可通过自学习功能,将这些文字的图像学习进入系统,使得调整后的核心可以支持这些文字的识别。
横向校对
将识别的原始图像块跟踪显示在识别结果上,使识别结果与原始图像一一对应的显示,方便修改错误,直观、方便、快捷。
纵向校对
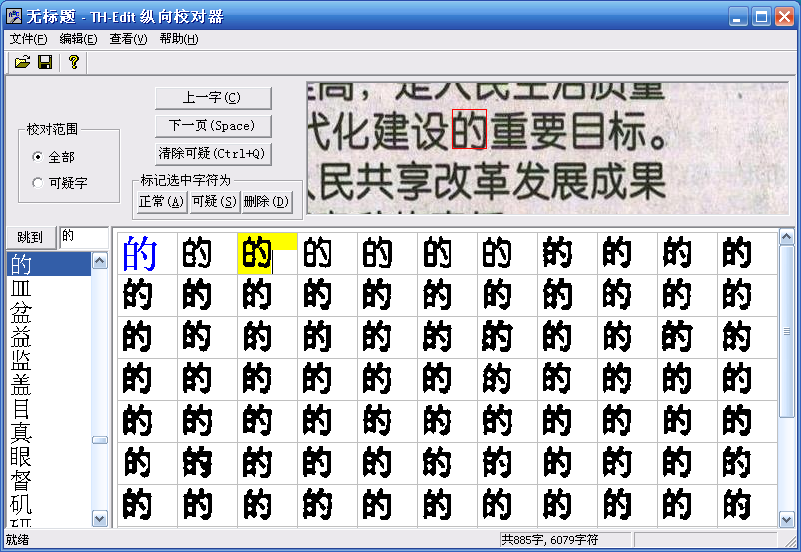
重新组织文字顺序,将识别结果相同的文字对应的图像显示在一起,不易遗漏错字,校对效率高,不易疲劳。
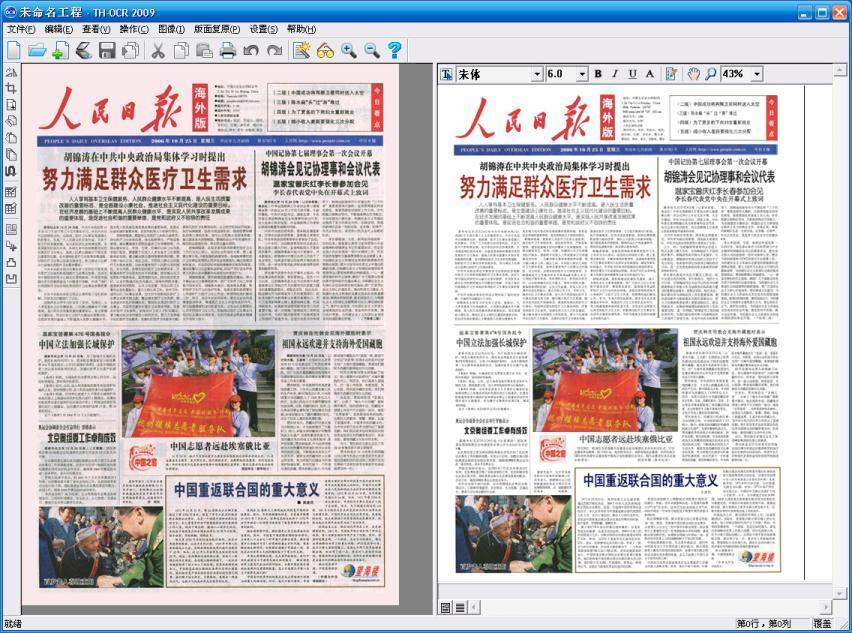
强大的版面还原技术
通过还原字体、字号、版面位置、字体颜色等信息,生成优质的全息PDF文档,将识别后的报刊、杂志、图书等多种形式的文档以原版原式呈现在读者面前。

多种格式导入和导出
支持TIF、BMP、JPG、PDF等多种图像格式文件的导入识别,识别结果经修改编辑后,可根据用户需求需要将文档存为可检索的RTF、双层PDF、TXT格式文档,精确还原版面。

TH-OCR综合文字识别系统(少数民族文字识别系统)
支持识别简体中文(繁体)、纯英文、日文、韩文、藏文、维文、哈萨克文、阿拉伯文等十余门语种。
通用文字识别系统
支持识别简体中文(繁体)、纯英文、阿拉伯文、手写文字,支持视频及场景文字识别。
综合文字识别系统-国产化
支持识别简体中文(繁体)、纯英文、手写文字,支持麒麟、统信UOS等国产操作系统,保证数据安全。

图书馆
中国国家图书馆、清华大学图书馆、上海交大图书馆、天津南开大学图书馆等上百家图书馆。
电力行业
国电信息中心、各省市电力设计院、各省市电力科学院

出版社、报杜
商务印书馆、中华书局、大连日报社、深圳特区报、南方周末
古籍识别技术领域得到充分肯定。
政府机关
中央办公厅、国家安全部九局、水利部、国家质量技术监督局、人民日报社、国家图书馆、中华书局、国电信息中心、中央办公厅、国家安全部、水利部等。
中安未来文字识别产品积极致力于为政府机关和各行各业改善和创造条件,加速现代化管理的进程。真正实现档案电子化,提高工作效率。为电子档案的广泛普及打下良好基石。
